Today, I'm going to talk about what volatile means in Java. I've sort-of covered this in other posts, such as my posting on the ++ operator, my post on double-checked locking and the like, but I've never really addressed it directly.
First, you have to understand a little something about the Java memory model. I've struggled a bit over the years to explain it briefly and well. As of today, the best way I can think of to describe it is if you imagine it this way:
At this point, I usually rely on a visual aid, which we call the "two cones" diagram, but which my officemate insists on calling the "two trapezoids" diagram, because he is picky. ready is a volatile boolean variable initialized to false, and answer is a non-volatile int variable initialized to 0.
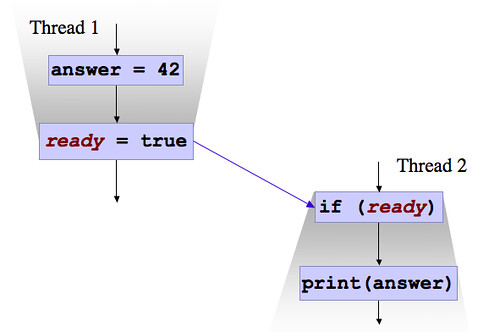
The first thread writes to ready, which is going to be the sender side of the communications. The second thread reads from ready and sees the value the first thread wrote to it. It therefore becomes a receiver. Because this communication occurs, all of the memory contents seen by Thread 1, before it wrote to ready, must be visible to Thread 2, after it reads the value true for ready.
This guarantees that Thread 2 will print "42", if it prints anything at all.
If ready were not volatile, what would happen? Well, there wouldn't be anything explicitly communicating the values known by Thread 1 to Thread 2. As I pointed out before, the value written to the (now non-volatile) ready could "leak through" to Thread 2, so Thread 2 might see ready as true. However, the value for answer might not leak through. If the value for ready does leak through, and the value for answer doesn't leak through, then this execution will print out 0.
We call the communications points "happens-before" relationships, in the language of the Java memory model.
(Minor niggle: The read of ready doesn't just ensure that Thread 2 sees the contents of memory of Thread 1 up until it wrote to ready, it also ensures that Thread 2 sees the contents of memory of any other thread that wrote to ready up until that point.)
With this in mind, let's look at the Double-Checked Locking example again. To refresh your memory, it goes like this:
However, this is only part of the solution. If one thread creates the object, it has to communicate the contents of its memory to another thread. Otherwise, the object will just sit in the first thread's memory. How do we communicate the contents of memory to another thread? Well, we can use volatile variables. That's why helper has to be volatile -- so that other threads see the fully constructed object.
Locking in Java also forms these "happens-before" communication points. An unlock is the sender side, and a lock on the same variable is the receiver side. The reason that doesn't work for (non-volatile) double-checked locking is that only the writing thread ever performs the locking. The whole point of the idiom is that the reader side doesn't do the locking. Without the explicit communication in the form of the volatile variable, the reading thread will never see the update performed by the writer thread.
Let me know if that makes sense.
First, you have to understand a little something about the Java memory model. I've struggled a bit over the years to explain it briefly and well. As of today, the best way I can think of to describe it is if you imagine it this way:
- Each thread in Java takes place in a separate memory space (this is clearly untrue, so bear with me on this one).
- You need to use special mechanisms to guarantee that communication happens between these threads, as you would on a message passing system.
- Memory writes that happen in one thread can "leak through" and be seen by another thread, but this is by no means guaranteed. Without explicit communication, you can't guarantee which writes get seen by other threads, or even the order in which they get seen.
At this point, I usually rely on a visual aid, which we call the "two cones" diagram, but which my officemate insists on calling the "two trapezoids" diagram, because he is picky. ready is a volatile boolean variable initialized to false, and answer is a non-volatile int variable initialized to 0.
The first thread writes to ready, which is going to be the sender side of the communications. The second thread reads from ready and sees the value the first thread wrote to it. It therefore becomes a receiver. Because this communication occurs, all of the memory contents seen by Thread 1, before it wrote to ready, must be visible to Thread 2, after it reads the value true for ready.
This guarantees that Thread 2 will print "42", if it prints anything at all.
If ready were not volatile, what would happen? Well, there wouldn't be anything explicitly communicating the values known by Thread 1 to Thread 2. As I pointed out before, the value written to the (now non-volatile) ready could "leak through" to Thread 2, so Thread 2 might see ready as true. However, the value for answer might not leak through. If the value for ready does leak through, and the value for answer doesn't leak through, then this execution will print out 0.
We call the communications points "happens-before" relationships, in the language of the Java memory model.
(Minor niggle: The read of ready doesn't just ensure that Thread 2 sees the contents of memory of Thread 1 up until it wrote to ready, it also ensures that Thread 2 sees the contents of memory of any other thread that wrote to ready up until that point.)
With this in mind, let's look at the Double-Checked Locking example again. To refresh your memory, it goes like this:
The object of the double-checked locking pattern is to avoid synchronization when reading a lazily constructed singleton that is shared between threads. If you have already constructed the object, the helper field will not be null, so you won't have to perform the synchronization.
class Foo {
private volatile Helper helper = null;
public Helper getHelper() {
if (helper == null) {
synchronized(this) {
if (helper == null) {
helper = new Helper();
}
}
}
return helper;
}
However, this is only part of the solution. If one thread creates the object, it has to communicate the contents of its memory to another thread. Otherwise, the object will just sit in the first thread's memory. How do we communicate the contents of memory to another thread? Well, we can use volatile variables. That's why helper has to be volatile -- so that other threads see the fully constructed object.
Locking in Java also forms these "happens-before" communication points. An unlock is the sender side, and a lock on the same variable is the receiver side. The reason that doesn't work for (non-volatile) double-checked locking is that only the writing thread ever performs the locking. The whole point of the idiom is that the reader side doesn't do the locking. Without the explicit communication in the form of the volatile variable, the reading thread will never see the update performed by the writer thread.
Let me know if that makes sense.
Comments
Nice post, you explain very well why the volatile keyword is needed and what are the effects of using it or not using it. Now, the thing about threads using separate memory spaces, I guess it is just artistic license to help you make the point right? :)
For example, most processors nowadays have local caches. If one thread is reading from and writing to a cache on one processor, it may not see the same value as another thread writing and reading from another cache on another processor, depending on the processor's memory consistency model.
That's one of the reasons why explicitly doing the communication is so important. One of the things that accessing a volatile variable effectively does on such machines is to say "reconcile the cache with main memory".
But yes, there is definitely a shared memory space. That's how the values "leak through".
@gabriel -- True. Since I was one of the co-authors of the new memory model, I take the liberty of pretending that the old one doesn't exist. :)
If i declare a long/double variable as volatile, will a write to that variable in Thread A be atomic?
Is it possible for Thread B to see corrupt values for volatile long/double types?
Vignesh
> If i declare a long/double > variable as volatile, will a write to that variable in Thread A be atomic?
Volatile guarantees your double, longs (64 bits) are atomic, though some very, very early (ie well before JSR 133) JVM's messed this up apparently, they were wrong to do so.
Thus the impact of volatile is bigger on a multi-core system than on a single core?
After Java 5, i think volatile guarantees "Happens Before" like synchronization.So, presence of volatile keyword for a variable ensures that the variables written to before write to volatile variable are not reordered by the compiler even though the other variables are not declared volatile.This is my understanding after reading Jeremy's previous posts on this.
Vignesh
(I realize this may not be a good example since any HashMap shared between threads would need to be synchronized regardless)
But is this behavior just a result of how modern CPU's *enforce* java's memory model? I don't remember if the JMM actually calls for this behavior.
Also, I am curious about your thoughts on Markus's question.
--V
That said, optimizations are possible to reduce the synchronization cost.
On the Java side, the write and the read need to be on the same variable - most of the times it does not matter except when static analysis performed by the JVM compiler can prove this is never the case.
On the JVM side, I think a smart JVM would not use any _cache_ flush on an uniprocessor machine. It would just need to actually perform writes of values kept inside registers.
And I also think that a multicore system with a shared cache would not need cache flushes, either.
int a = aVolatileVariable;
return;
a write one with:
aVolatileVariable = 0;
and a full memory barrier with
aVolatileVariable = aVolatileVariable;
? I'm pretty sure the compiler wouldn't be allowed to optimize the otherwise meaningless operation away, but I could have overlooked some detail.
Having said that, YMMV. There is often a cost associated with volatility. Consult Doug Lea's JSR-133 cookbook for a lot of detail.
Nope. You are just doing a volatile read in that case -- a read of the reference to the HashMap. You have a receiver, but no sender.
As you point out, you would never want to do this, because you would have broken behavior (including the infamous HashMap infinite loop).
It's guaranteed by the memory model. In memory model language, all writes to a volatile field happen-before any subsequent reads of that volatile field. In the language I used in this post, all of those writes are sending, and any subsequent read is receiving from all of them.
I want to underline that there are compiler optimizations that can affect this -- so the JVM has to be careful not to reorder with abandon around loads and stores of volatile fields. So there is still an impact on uniprocessors.
I keep meaning to do a post on synchronization optimizations.
I find the phrase "memory contents the thread sees" ambiguous... I'm sure it's just me, but what exactly does this mean? memory contents that may be cached in the current scope, memory contents that may be cached anywhere on call stack, or...?
Thanks.
if the vm is allowed to optimise it away because it isn't accessed by multiple threads, than it doesn't do any damage. As long as it doesn't allow these read and write barriers to be removed when they should not.
I'm struggling with the same problem. If you want to understand the JMM you need to play on the edge and in some cases fall over. But I would like to know for sure that I don't fall over in this case, so the read/write/full barrier isn't removed when there is some JMM value.
ps:
I came up with the same implementation for read/write/full barrier and would like to know for sure that it works.
If the JMM insists that there will be a happens-before relationship, then the relationship has to be enforced by the JVM (otherwise there is a bug).
A question about 'happen-before'. This memory barrier is between 'write' and 'read' only?
I'm a little confused if there are two threads writing to the same volatile variable. Does 'happen-before' still hold?
For example,
Thread #1
answer = 42;
ready = true; // write
Thread #2
ready = false; // write
print answer;
Can I expect to see answer=42 within Thread #2? Or the memory barrier works only write/read?
Thank you.
Also, some commentors mentioned of HotSpot run-time optimization. Can someone point me to the right direction on how I can learn more about it. I tried Sun 1.6.10 debug JVM with -XX:+PrintOptoAssembly option but hard time reading the output. I want to learn more about it. I am getting interesting result regarding hotstop and infinite loop and trying to understand more about it. Thanks in advance.
The -XX:+PrintOptoAssembly output is fairly low level; I don't know of any clear reference on it.
@Jeremy(1): I had such a feeling about LFENCE (i.e. that it wasn't needed most of the time), but the Intel manuals are not that easy to follow about this. What you said about volatile reads, however, is really important (and I hope it extends to x86_64).
@Jeremy(2): you are right about the aVolatileVariable thing. I forgot to mention that the plan was to do that onto a static volatile, creating static members:
MemoryBarrier {
private volatile Object dummyVar;
public readBarrier();
public writeBarrier();
public fullBarrier();
}
with the bodies I wrote in my previous post.
One could also make them nonstatic, to allow conceptually independent memory
barriers to be executed. Unlike the existence of separate locks, that's useful just to make the source self-documenting, unless one is using a useless barrier, and the compiler can prove that (which means you
really screwed it up).
I'm used to memory barriers from C programming, and I have some reasons for
bringing them to Java: in some cases, doing this is much simpler than making
"almost immutable" data, which is not set by a constructor, actually immutable (in some cases you'd have to rework the class diagram just for this, or create horrible dummy classes, like I did a couple of times), and maybe it can be faster than making a field volatile if it is set just at one point (if one is able to avoid doing a read barrier for each read access). I'm not sure about the last point though.
As for the other case, I think that what you want is probably an interface that looks like:
SomeClass.publish(foo);
which will safely publish foo without implying fence semantics. The JMM has this for final fields, but we've never worked this out for non-finals.
Doug Lea is currently talking about a Fences API:
http://g.oswego.edu/dl/concurrent/dist/docs/java/util/concurrent/atomic/Fences.html
But I think that it will be very difficult for the average programmer to use, and we'd be much better off with something that actually encapsulated the use cases correctly.
@mikey: Thanks!
I am wondering if I can use the volatile keyword for cache of singletons.
Suppose I have a search engine framework, and there are several types of searches. For each type, there is a search engine class. And I want to keep only one instance of search engine for each type in memory. So I will use a HashMap as the cache, with search type as the key, and search engine instance as the value.
Now there are two concerns. The first is that if a thread may get a search engine instance which is not fully initialized (the same problem as in Double-Checked Locking). The second concern is that after a search engine is created and put in the cache (HashMap), can other thread get it from the cache.
I came up with the following code, let's see if there is any problem there.
public class SearchEngineStore{
//I don't use ConcurrentHashMap, because at worst only few threads (at the beginning) don't see the updated cache and have to enter the synchronization block.
private static Map<String, ISearchEngine> cache = new HashMap<String, ISearchEngine>();
private volatile static ISearchEngine newEngine = null;
public static ISearchEngine getEngine(String searchType){
ISearchEngine engine = cache.get(searchType);
if (engine == null){
synchronized(cache){
engine = cache.get(searchType);
if (engine == null){
newEngine = SearchEngineFactory.newInstance(searchType);
//since the newEngine is a volatile variable, the next 2 steps shouldn't be executed until the initialization in the above step finishes. (Am I right?)
engine = newEngine;
cache.put(searchType, engine);
}
}
}
return engine;
}
}
IMHO the simplest thing is to avoid any tricks (like that volatile field, which is a clear hack) and use ConcurrentHashMap. If you want more speed, try with Cliff Click's version of ConcurrentHashMap.
But before doing that, consider if you need at all to optimize this. Do you have a performance problem at all? If not, just use synchronize the straight way: no access to shared variables except under synchronized.
Basically, your error is that you think implicitly synchronizing the write side is enough. Appropriate locking should be inserted also on the read side - I'll refer to this below.
First, you do have exactly the Double-Checked Locking problem. If the first unsynchronized map lookup succeeds, nothing guarantees you that the effects of the object constructor are visible, even if insertion is done under a lock, because the read side can run without synchronization.
Also, in some cases, even if the Map were thread safe by itself, if it does not give happens-before guarantees, you can still get the above result. Cliff Click's NonBlockingHashMap may be such an example (but I don't know, its documentation is not clear on this). More important, the write and the read need to be atomic, so you need in any case a synchronized block to make them indivisible.
Then, there is this comment:
//I don't use ConcurrentHashMap, because at worst only few threads (at the beginning) don't see the updated cache and have to enter the synchronization block.
You are accessing an HashMap through a data race, because it's shared and you read it without locks, and you should not. Even the assumption that the updated value will eventually be visible is not guaranteed by the JMM (if the value is copied into a register and kept there, this might show up in practice, in simpler examples).
Then:
//since the newEngine is a volatile variable, the next 2 steps shouldn't be executed until the initialization in the above step finishes. (Am I right?)
Maybe you are right (I think the reordering may be possible actually), but the read side has no read of newEngine, so it should be allowed to see a race going on, and on systems were read barriers are needed, the problem will show up in practice.
Another thread doing an insertion will read newEngine and so it'll be safe - but that's already guaranteed by the synchronized block.
In fact, replacing the innermost if with this block will produce no change:
if (engine == null){
engine = SearchEngineFactory.newInstance(searchType);
cache.put(searchType, engine);
}
since it is contained into synchronize.
Writes done before a volatile write operation A are visible for sure after you do a volatile read that see the result of action A. Writes done after A may be moved before it.
It's simpler to think "if no data race exists, I can expect safely sequential consistency", i.e. each action will be executed atomically, they will be visible in the same total order for every thread, and there will be no visible reordering. Like if all threads were multiplexed on a single processor. That's more or less the definition used by the new C++ Memory Model, which will be a simplified version of the Java one.
Thanks for your comment. Let me make sure I understand you correctly.
1. ConcurrentHashMap (or other synchronized version of HashMap, or synchronization block for the read/write) must be used, otherwise, the hash map may just crash.
2. Even the thread doing an insertion flushes changes to the main memory when it exists the synchronization block, the thread doing a read without synchronization may not see all the effects: it may see only the HashMap.put() effect but not the object initialization. This results in a successful "get" from HashMap with an uninitialized object (just the same problem in DCL). That means, my attempt of using volatile variable to make sure the read thread sees the fully initialized object just failed.
3. It seems there is no other solution for this particular case than making the whole method synchronized. Do we?
Paolo, are you sure that "Writes done after a volatile write operation may be moved before it"? For example:
Step 1. Set A=1
Step 2. Write to a volatile variable
Step 3. Read from the same volatile variable
Step 4. Set A=2
If step 4 can be moved up, then how can we guaranteer the state when the volatile variable is read?
Thanks again!
For this case, you could try using ConcurrentHashMap with putIfAbsent:
private static Map<String, ISearchEngine> cache = new ConcurrentHashMap<String, ISearchEngine>();
ISearchEngine engine = cache.get(searchType);
if (engine == null) {
engine = SearchEngineFactory.newInstance(searchType);
cache.putIfAbsent(engine);
}
If you really can't handle ever accidentally creating a new instance of SearchEngine, then you could use synchronization for mutual exclusion here:
private static Map<String, ISearchEngine> cache = new ConcurrentHashMap<String, ISearchEngine>();
...
ISearchEngine engine = cache.get(searchType);
if (engine == null) {
synchronized (cache) {
engine = cache.get(searchType);
if (engine == null) {
engine = SearchEngineFactory.newInstance(searchType);
cache.put(engine);
}
}
}
The fact that it is a ConcurrentHashMap papers over the memory model difficulties.
1st part: I agree on most points, at a basic level. I would correct point #3 to say "there is no _simple_ solution to do that, but moreover it's just not worth it".
But you may wrap a ConcurrentHashMap to handle failed lookups by creating the new value - that's the only simple&clean solution, which does not clutter sources. See http://code.google.com/p/concurrentlinkedhashmap/wiki/SelfPopulatingCache
> 2. Even the thread doing an insertion flushes changes to the main memory when it exists the synchronization block, the thread doing a read without synchronization may not see all the effects: it may see only the HashMap.put() effect but not the object initialization. This results in a successful "get" from HashMap with an uninitialized object (just the same problem in DCL).
That's correct, as long as "may" is intended as "that's one of the various possible reorderings" - it's simpler to assume undefined semantics for data races. Semantics are actually defined, but relying on them is a bad idea, and I'll let Manson elaborate on this if ever needed. Never studied them indeed.
> That means, my attempt of using volatile variable to make sure the read thread sees the fully initialized object just failed.
Yep :-(.
2nd part: in your example, step 4 cannot be moved up just because of the read.
The solution I came up with was to use directly putIfAbsent() to insert a placeholder, and do the computation if the insert succeeds, calling notify on the placeholder at the end; on failure, if a placeholder was found, wait on it for the computation to complete and return the result; if a non placeholder object was found, return it.
All this is encapsulated inside the implementation on top of a ConcurrentMap; the client code performs a cache lookup, a computation and a cache update. It looks like the code is very similar to the one for SelfPopulatingCache, except for the client API, and for the fact that I didn't know I could use Future instead of writing explicit synchronization code; however, I could guarantee that notifyAll() is not needed nor called (each awaken thread notifies the next one just after the wait on the placeholder and before releasing the lock on it).
Any opinions on the two alternatives?
I think it's better to change your example which uses "putIfAbsent" to the following:
......
engine = cache.putIfAbsent(engine);
......
This makes sure that the method always returns the same instance (the one put in the ConcurrentHashMap), then the extra engine may just be garbage collected.
Your next example works because ConcurrentHashMap uses volatile variables, which guaranteers that search engine initialization happens-before the insertion into the hashmap, which happens-before the read from the hashmap.
Thanks you two! I learned a lot.
About the first point: Jeremy posted the code up to the insertion, so the buggy behaviour you get when inserting Jeremy's comment in the original method was not intended.
This is a fairly nice optimization if you are backing the local cache with a remote caching layer. That's how my production version of the tutorial's SelfPopulatingMap works (its a fairly simple enhancement).
What's the point of the proxies and what does it mean "warming the proxies"? How are subsequent calls blocked (wait on a semaphore), and what is the unnecessary work you save?
How is this all related to the use case you describe about a local remotely backed cache?
Imagine you need to retrieve 10 objects, say to show on a paginated form. You could retrieve each sequentially, perhaps with 3 found and 7 needing to hit the data store. The worst case is O(n).
Now, what if you add a getAll() method to the map and have a BulkEntryFactory? The worst case is now O(1), as they are retrieved in parallel. Even if all you can do is get one at a time from the system of record (database), you might put in place a 2nd-level cache (like memcached) and still get O(1) if its warmed. So there's a nice performance boost.
To implement, you could perform the operation and populate the map afterwards. But, if you're retrieving #1-10 and another request wants #6, its duplicate effort to miss and load the data. Instead you can place ten proxies into the map so that any subsequent request blocks on the proxy waiting for it to load. The bulk task is executed and the proxies are run to warm their slot from the bulk's response. This also unblock anyone waiting, giving you both a better hit rate and O(1) efficiency.
But how does the API allow the map to know all the keys? Or is the method getAll(Collection keyCollection)?
Finally, it seems you don't replace the proxy with the actual element, do you? OK, I can see that in a map with eviction one might want to have a proxy always in place (when it is first installed) with a get() method, to reduce write access (and possibly lock contention) on the map.
And yep, once the proxies are warmed, there's no need to replace them. I can post the code if interested.
http://cs.oswego.edu/mailman/listinfo/concurrency-interest
It's a great place to ask this sort of advice from a wide range of experts, as much as my ego would make me believe that I am a good single-source for this stuff.
How to implement a SelfPopulatingMap
......
engine = cache.putIfAbsent(engine);
......
It should be:
......
ISearchEngine previousEngine = cache.putIfAbsent(engine);
if (previousEngine != null)
engine = previousEngine;
......
That's to say, method putIfAbsent() returns null if there is no value of the specified key in the map before the insertion. It won't return the inserted value.
To call this function from foo, constructor should be public. If its a public constructor, where is the point of Singleton ?.
Helper object can be created very much from its public constructor isnt ??
Otherwise, I think that you can replace "Foo" by "Helper" in the class declaration and make getHelper static, so that you get the singleton instance with a call to Helper.getHelper().
In both case, you get a meaningful example.
Could you please give sample java code with threads to experience the use of volatile in java.
Thanks.
This is the code i used.
Even now only one object is created (Value of one thread is seen by other)
without using the volatile keyword.
Is my understanding right?
If i am wrong, could you please give me some more explanation or sample code to experience the importance of volatile keyword.
Thanks.
class Foo {
private Helper helper = null;
public Helper getHelper() {
try {
Thread.sleep(1000);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
synchronized (this) {
if (helper == null) {
helper = new Helper();
System.out.println("Creating new helper......");
}
}
return helper;
}
class Helper {
private int id;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public boolean isStatus() {
return status;
}
public void setStatus(boolean status) {
this.status = status;
}
private boolean status;
}
public static void main(String args[]) {
final Foo foo = new Foo();
//For concurrency using thread technique
for (int i = 1; i < 1000; i++) {
new Thread() {
public void run() {
for (int i = 1; i < 100; i++) {
new Thread() {
@Override
public void run() {
foo.getHelper();
}
}.start();
}
}
}.start();
}
}
}
Output:
run:
Creating new helper......
BUILD SUCCESSFUL (total time: 45 seconds)
I'll try.
If you have any java code (concurrency) which behaves differently for two scenarios:
1. With volatile keyword.
2. Without volatile keyword.
Please post the java code so that i will get the exact usage and understanding on "volatile" keyword in concurrency.
Thanks.
states that synchronized guarantee happens-before. I feel there is no need for volatile.
As per above link synchronized method/block both guarantee happens-before. double locking using volatile field and synchronized block is not needed.
regarding your example, I think it would be very important for "beginners" to clarify if the variable "answer" also has to be volatile or not!
In your example the variable "ready" needs to be volatile in every case. But what about the variable "answer"? does the "volatile ready variable" implicitly make "answer" also volatile? thats nowhere stated in your explanation or does the programmer explicitly have to declare answer volatile to get the "happens before" relationship.
it would be kind if you can answer this question.
thanks!
Or, another way: everything that happens-before the write to ready is ordered before and visible to everything that happens after a read that sees that write. The write to answer is therefore ordered before and visible to the read of answer.
Just need to make sure, So for the case of Collections.synchronizedMap which return synchronized-wrapper map.
If thread-A put something to this synchronized-Map,
Thread-B can read the value that thread-A has put into the map (happen-before).
Is this right? Because synchronizedMap Wrapper use the synchronized-block on the same mutex-object monitor for all map access-methods.
Another question is ... For all concurrent-collection classes in java.util.concurrent package, has this happen-before semantic right?
Br,
Suttiwat
But one point is still unclear for me. As I understand variable answer “leaks” to the Thread 2. This is called "happens-before"? It’s already implemented in JVM.
But what means does JVM use to do this?
Which optimization should be removed in this case? For example “answer” can be cashed in the register in the Thread 2. How does JVM know that it should reread this value from memory?
What JVM and compiler can do to prevent this situation?
could you help me understand the trick used in 'put' method of segment in ConcurrentHashMap (jdk 1.6)? Volatile write in entry constructor might be reordered with assignment of this entry to entry array slot.
I'm looking at
http://gee.cs.oswego.edu/dl/jmm/cookbook.html
and I'm a bit puzzled: compiler is still allowed to reorder volatile field ('value') write with another volatile field read ('table').
We speak about the case when reader sees published incomplete 'HashEntry' reference.
if lets say i have a seqNum inside a class called Sender
i want to make this seqNum a static and volatile
static because it is shared among all instances of class Sender
each Thread has its own instance of Sender , ther is no multithreading here but since multiple Sender objects will send and increase teh seqNum , i want to have a seqNum which will have most recent seqNum instead of each instance of Sender having seqNum .
for this purpose i want to make seqNum a static and also volatile.
is this correct approach?
please post your comment
thanks
Pramod
This will not work. Please see my blog entry here:
http://jeremymanson.blogspot.com/2007/08/volatile-does-not-mean-atomic.html
@Jeremy Manson: how much slower is AtomicLong than AtomicInteger, on a 32bit platform (say, x86)?
Thanks!
If i change the "ready" from volatile field to AtomicBoolean,Is the example also thread-safe?
So what you imply is that write to a volatile causes a write barrier execution and a read from a volatile causes a read barrier execution.
Is that correct?
If so, was this the semantics of the volatile keyword even prior to Java 1.5?
Thanks,
Abhay.
Prior to Java 5, volatile had no special semantics. They gave it some semantics, but upon closer inspection, the semantics they gave it were indistinguishable from the semantics of normal fields.
If volatile is just for communicating the value of global variable for other threads why can't I use a static global varible.
Any updates made to static variable will be reflected in other threads if they hold different instances even.
correct me If I am wrong
This article very much confused me. It just further enhanced the confusion.
Therefore, if you don't explain what's your problem with the content, nobody can really help you.
I would suggest you to stick with this article, read it again, and ask specific questions, instead of looking for better articles (which I don't think exist).
Btw, volatile is not a new keyword in Java 5, it just has a different (and much less stupid) meaning, so that you should not use it with older Java versions.
Would it be safe to say that a volatile read is as good as an entry into a synchronized block of code. Whereas a volatile write is equivalent to a synchronized block exit. Ofcourse, without the mutual exclusion part.
If two thread enters in the block.both will find helper = null,
thread 1 enters synchronized block.creates Helper object,release lock.thread 2 enters,ideally it should not find helper as null.what is the case when it finds it null?
In some articles I have read that if refernce has been created to Helper object but its variables still have default values,in this case thread 2 will also create Helper object.
So my question is how volatile helps to overcome this problem?
Please see my previous post here for the details:
http://jeremymanson.blogspot.com/2008/05/double-checked-locking.html
Does somebody know a similar article about C++ 11 Atomic type ?
2) difference between a volatile static variable and volatile instance variable
3) you said that volatile from java 1.5 on-wards provides 'happens-before' behavior. But are there any differences w.r.t to above 2 questions comparing java 1.4 and the later versions?
4) what is the best method of implementing a singleton class prior to java 1.5 (assuming a multi-threaded application)?
1) No difference that doesn't also apply to non-volatile variables.
2) No difference that doesn't also apply to non-volatile variables.
3) Nope.
4) For static lazy initialization, use the initialization on demand holder pattern (look it up). For instance lazy initialization, use locking.
1.Volatile variable can be stored in either CPU local registers or Main memory. Is it correct?
2.Suppose volatile variable ‘vObject’ is a Object and it is stored in CPU local registers
a.In Java we have two kinds of memory stack and heap. Does registers maintain the same?
b. If ‘vObject’ is a used in Thread1 and Thread2. Does these two threads will have own copy of this variable in their local registers.
1) Register allocation vs memory is probably not the best way of thinking about this when trying to reason about the correctness of your code. Even from an architectural point of view, it doesn't take into account the effect of cache coherence protocols. In practice, volatiles are very unlikely to be register allocated, simply because updates need to be made visible to other threads quickly.
2) I'm not sure what you mean by an object being stored in registers. If vObject is a volatile variable, it would be a reference to an Object, not an actual Object.
{
volatile int testValue = 0;
public VolatileExampleThread(String str){
super(str);
}
public void run(){
for(int i = 0; i<10; i++){
try{
if(getName().equals("Thread 1 ")){
testValue = 10;
}
sop(getName()+",testValue="+testValue);
Thread.sleep(1000);
}catch(InterruptedException exception){
exception.printStackTrace();
}
}
}
public static void sop(String message){
System.out.println(message);
}
}
public class VolatileExample {
public static void main(String args[]) {
new VolatileExampleThread("Thread 1 ").start();
new VolatileExampleThread("Thread 2 ").start();
}
}
output is always:
Thread 2 ,testValue=0
Thread 2 ,testValue=0
Thread 1 ,testValue=10
Thread 2 ,testValue=0
Thread 1 ,testValue=10
Thread 2 ,testValue=0
Thread 1 ,testValue=10
Thread 2 ,testValue=0
Thread 1 ,testValue=10
Thread 2 ,testValue=0
Thread 1 ,testValue=10
Thread 1 ,testValue=10
Thread 2 ,testValue=0
Thread 1 ,testValue=10
Thread 2 ,testValue=0
Thread 2 ,testValue=0
Thread 1 ,testValue=10
Thread 2 ,testValue=0
Thread 1 ,testValue=10
Thread 1 change the volatile variable testValue to 10 but not reflect in Thread 2.
Can you please explain on this?
public class NoVisibility {
private static boolean ready;
private static int number;
private static class ReaderThread extends Thread {
public void run() {
while (!ready)
Thread.yield();
System.out.println(number);
}
}
public static void main(String[] args) {
new ReaderThread().start();
number = 42;
ready = true;
}
}
Interesting this does not seem to work as suggested on the X86 platform. I thought the X86 architecture guaranteed that if you can see one update to memory then you would see all other updates, that the same thread had made up to that point?
So on an X86 platform you would always see 42, never 0. I think Sparc in TSO mode works the same?
Keen to see some real example that can be executed on a given platform preferably X86.
1) Nothing is volatile in that example. If ready were volatile, you (should) be guaranteed to see 42.
2) Re: x86: The Java memory model is looser than x86, because Java allows compiler transformations that increase possible program behaviors. So you would be allowed to see 0 in the example as it stands.
What I was initally looking for was some real life examples that I could run on a modern X86 SMP machine, with a modern VM (I am usinging Java HotSpot(TM) Client VM (build 16.3-b01, mixed mode, sharing)
When I ran the example above I always got 42.
So doing some research I came upon your blog entry.
My now more thorough understanding of modern X86 and Sparc architectures is that once a write becomes visible to other processors, then all previous writes by that same processor must also be visible, (TSO), power PC does not make such guarantees. I think this why Volatile would have worked on X86 even in 1.4, even though some authors say that is was broken.
So in the example the only time that 0 would be printed is if the VM or the processor reordered the actual instructions executed such that ready=true was executed before number=42.
If for example I modified the main method as follows:
public static void main(String[] args) {
new ReaderThread().start();
number = 42;
ready = number==42?true:false;
}
the intention being that I don't want the VM or the processor to reorder the number and ready assignments, then I could always expect 42 on X86 and sparc processor, without using the volatile keyword.
I am struggling to see a case where 0 could ever being printed on a X86 SMP machine.
Though I could see situation when infinite loop was created if the processor never re read the value of ready from main memory.
So to be be specific would you agree with my post?
And would you have some example code that I could run on X86 that demonstrates such reordering without volatile?
In this case, the JIT compiler won't even compile the code, because Hotspot's JIT doesn't kick in until ~10K iterations of the same code. The call to Thread.yield() (since it is a native invocation) is also likely to kill such optimizations. But you are not guaranteed to get it to do such optimizations on any given code; I gave it as an example because it is cut down and easy to understand.
However after looking hard I can not find any examples runnable code where JIT actually does any such re-ordering. Is that becuase I am not looking hard enough, or that it does not exist currently?
-Mark
while (!ready) {
// stuff
}
never terminates regardless of what assignments to ready occur in other threads, so yes, the JIT compiler does take advantage of this flexibility.
Just following up my posts to say that I was able to modify the original program to enter an infinite loop using Java(TM) SE Runtime Environment (build 1.6.0_20-b02).
I had to run the program in -server rather than client mode, and made some small changes, but it reliable does do an infinite loop.
public class NoVisibility {
private static boolean ready;
private static int number;
static int foo;
private static class ReaderThread extends Thread {
public void run() {
while (!ready)
foo++; // do something intense, doing IO is enough to change the
// compiled code so that ready will get reread from main
// memory at some point.
// Thread.yield();
System.out.println(number);
}
}
public static void main(String[] args) throws Exception {
new ReaderThread().start();
number = 42;
Thread.sleep(1000);
ready = true;
System.out.println("just to prove foo is updated as you go along:"
+ foo);
}
}
One thing that I have not been able to show is to get the JIT compiler to reorganise the assignments of ready and number to an out of order sequence, which I believe is the only way to get 0 to print on an X86 or sparc platform. I can't find any evidence of any JVM that reorders writes such that they are out of sequence, though I understand that spec would allow for it. The X86 and sparc platforms wont allow such out of sequence reorderings. Can you think of any java compilers that would reorder writes out of sequence?
BTW your blog is an excellent resource!
-Mark
You could easily imagine that there might be some sort of cache-aware or pipelining optimization that would cause such an effect, but I don't know of any real examples of those in practice.
-bluecoder008
First of all nice post.
I have a bit of a question though (not nearly as technical as most of the comments here)
I have an Cache Manager object which is accessible to all threads in my app server. The object contains the cached value (lets call it Y) which is an simple object reference (not a primitive, not declared volatile) and there is a simple getter method exposing the value Y.
On server startup an initial value for Y is loaded.
There is another thread which every X minutes will refresh the value for the cache and simply reassign the Y value.
Now I know this isn't thread safe, when Y is set different threads may see the old or new value of Y for a while, but for this case its not important at all ... my question is, is there any other problem with that? My understanding is that the new value of Y will "leak through" to all threads eventually ... and eventually is a very small amount of wall clock time.
Just asking because I've had this argument over and over with people about wether you need synchronised locks, read/write locks, volatile ... and my understanding was that if we don't care there is no issue there, but I've never had anything to say that there isn't a problem there ... because almost all resources about concurrency are talking about examples when you are worried about thread safety.
Thanks
Steve
In practice, this is unlikely to happen.
However, making the reference volatile is very low-cost on x86 (reads are basically free, writes don't cost much, and it sounds as if you aren't doing writes very frequently, anyway), so why not buy yourself something that is both good documentation and more correct?
Thanks for the reply ... in practice I've been using the volatile in this situation since I've know it existed.
I think when I first encountered this situation I was a fresh grad out of Uni and didn't even know that volatile existed ... and I guess the senior guys on the project at the time didn't either.
Cheers,
Steve
"2) Re: x86: The Java memory model is looser than x86, because Java allows compiler transformations that increase possible program behaviors. So you would be allowed to see 0 in the example as it stands.
March 13, 2012 at 10:01 PM "
Do you mean here JIT compiler or the compiler to the bytecode?
Nevertheless if a compiler does not perform instructions reordering, the code of anonymous from March 13, 2012 at 7:01 AM would be correct on x86? For example if I use JNI and write the code that assignes values to variables "ready" and "number" in main() and while loop from run() method in assembly, would it be always correct on x86 with MESIF protocol?
I believe that the code you reference would be okay on x86 without compiler intervention. x86 generally respects store order. There may be some caveats I'm not remembering off the top of my head.
what happens if the 'if part' is called before assigning the boolean value to ready variable. Then it wont print the output. U cant say it as happens before relation. Happens-before should make sure that ready part is initialized by a thread i.e the thread 1 has called the if part and then if check part is called. Volatile just synchronize and give correct read and write of data
I have a question which has already been asked in this blog but I dint quite understand your answer. It is:
"What happens if a third thread writes to x, after the volatile boolean ready has been set to be true by the first thread? What value for x will the second thread see?" In this case, the write to x doesnt happen before the write to ready. So, its not guaranteed to be read correctly by the 2nd thread, is it? Also, what if the write to x were done by thread 1 or 2 itself, i.e. if there are only 2 threads in question?
Thread 1:
answer=42;
ready=true;
x=1;
Thread 2:
if (ready) {
print(answer);
print(x);
}
Pardon me if my question sounds naive. I am still trying to sink in this concept.
In the example you posted, thread 2 can either print the original value or the value 1. You don't really need to worry about reordering in that case: just imagine that Thread 1 is suspended after the value true is written to ready.
thanks for the wonderfull blog. please keep blogging.
Anyways, I have a little doubt regarding volatile variables in java.
Please see below
class A {
private volatile boolean flag;
private int i;
private int j;
private boolean boolean
public void methodW() {
i=1;
flag = true; // volatile write
boolean temp = flag :// volatile read
j=1;
}
public void methodR() {
sysout("i = " + i); // write i
sysout("j = " + j) ; // write j
}
}
Suppose methodW and methodR are being accessed by different threads.
Then is there a possibility of output being
as
i = 0
j = 1
According to the
1. roach motel model.
2. and http://g.oswego.edu/dl/jmm/cookbook.html
The above output is not possible. because
i=1
j=1
will not be reordered.
but according the answer of this question
http://stackoverflow.com/questions/17169145/is-this-a-better-version-of-double-check-locking-without-volatile-and-synchroniz
the above output is possible
because JMM is a weaker model than Roach Motel Model
i just wanted to know which of the thing is correct.
void fun() {
double total = 0;
for (int i = 0; i<NUM_OF_STUDENTS; i++) {
total += getStudentScore(i);
}
double average = total/NUM_OF_STUDENTS;
}
it is possible this function execute on different processors. if a processor write to its cache without update cache of other processor, then it would be a problem for single thread application too.
volatile boolean b = false;
Thread 1
b = true;
Thread 2;
while (!b) {}
But that's going to waste a LOT of CPU on thread 2.
Having said that, there are times you can get away with this. Unless you know what they are, I don't recommend using it, though.
Can you elaborate on "When one thread writes to a volatile variable, and another thread sees that write, the first thread is telling the second about all of the contents of memory up until it performed the write to that volatile variable." ?
Vikrant here
I'm not sure I can elaborate any better than the original post plus the seven years' worth of clarifying questions in the comments do. If you have a more specific question, I can try to answer it.
Thanks for this useful post. So this case of using 'volatile' makes sense only in multiprocessor machines. In single processor machine with only one core for example, there is no need for 'volatile' even though there may be multiple threads sharing a particular variable. Correct? Thanks in advance.
Regards,
R.Pradeep
For your double checked locking example, you said that "Without the explicit communication in the form of the volatile variable, the reading thread will never see the update performed by the writer thread.".
I'm thinking that the volatile keyword may not be necessary since the "synchronized(this)" will also establish happens-before order such that the initialisation of helper will leak to other threads. For example, suppose helper is not volatile and a thread t1 initialised helper with new Helper(). However, another thread t2, which hasn't observed such initialisation of helper, will get into the critical region specified by "synchronized(this)" which establishes a happens-before order between t1 and t2. Thus t2 will see that helper is not null and leave the critical region without doing anything.
So I guess without specifying helper as volatile, the double-checked locking still works and using whether volatile or critical regions to establish happens-before order is just a trade-off of performance.
Regards,
Chunbai Yang
There is an ongoing discussion about if the volatile field is required in double-checked locking on stack overflow. Link :
http://stackoverflow.com/questions/34149824/is-it-advisable-to-always-use-volatile-variables-with-synchronized-blocks-method/34150353?noredirect=1#34149999
hi ,Jeremy,
thanks for the great post.
from your 2-thread example, it shocked me.
from your example, the volatile writing thread will leak through all content to the read-thread, right?
but what will happen if the write thread assign the answer 42, then do a lot of things,perhaps one minute later, then the write thread had finally written the isReady =true,
you mean at that time, the read-thread can read all the content of the write-thread??
in my view,it looks like the little volatile had flush all the content from write thread to read thread, the read -thread get update all values.
is my view correct?
and what happen if the answer field is not an int ,but an hash-map, the write thread insert 42, then after 1 minutes, write the isReady(volatile) ,
the read-thread can check the isReady, if it is true,then the read-thread can read 42 from the hash-map?
Hi!
Question - in your example with answer and ready - can't the compiler reorder the program instructions to make the "write to answer" happen after the "write to ready"?
If a program writes to a volatile variable, does that mean any writes that were coded to appear before the volatile-write will never be reordered to happen after that volatile-write?
If a program writes to a volatile variable, all of the writes that happen before it will be ordered before following reads of that volatile field, and visible to reads that happen after it. That doesn't say that the writes can't be reordered. If, for example, there are no following reads of that volatile field, the compiler can do whatever it wants.
In the above example, if the compiler could determine that nothing ever ready the ready field, it could do whatever reordering it liked.
Consider the snippet taken from JCIP:
// Unsafe publication
public Holder holder;
public void initialize(){
holder = new holder(42);
}
public class Holder{
private int n;
public Holder(int n) {
this.n = n;
}
public void assertSanity(){
if (n != n)
throw new AssertionError("This statement is false.");
}
}
The authors of the book suggests a solution-
1) public static Holder holder = new Holder(42);
Also if the requirement was to prevent AssertionError, this would also work fine-
2) private final int n; // initialisation guarantee
3) public volatile Holder holder = new Holder(42);
I would say this one will also work fine. Why beacause when thread A writes to a volatile variable and subsequently thread B reads that same variable, the values of all variables that were visible to A prior to writing to the volatile variable become visible to B after reading the volatile variable.
Even though declaring holder as volatile does not make its fields volatile, but yes it's enough in 3rd case. My reason would be due to the transitivity of happens-before relationships, the reference/holder won't be accessible to all threads until after the constructor has completed and (therefore) all fields(n in this case) have been initialized.
Please cdo correct me if I am wrong for 3rd scenario.
4) public void initialize(){
holder = new holder(42); // LET THIS BE AS IT IS
}
public class Holder{
private volatile int n; // making it volatile
.....
I surmise this would also prevent AssertionError due to n being volatile.
IS MY UNDERSTANDING CORRECT. Would really request you to voice your opinion in all 4 cases aforementioned.
For two and four: the methods suggested do guarantee that the field itself will be seen correctly. However, before that happens, you need to publish a reference to the enclosing object to the thread that executes assertSanity, and that should be done safely. Whatever method you use for safe publication should be sufficient to ensure that the AssertionError doesn't fail. For example, you can use method 1 or method 3, or use a lock:
final static Object lock = new Object();
Thread 1:
synchronized (lock) {
h = new Holder(42);
}
Thread 2:
synchronized (lock) {
if (h != null) {
h.assertSanity();
}
}
would there be any difference if we made "answer" volatile as well?
Is there a special reason not to do so?
Thanks,
L
Many thanks for this article. I'm very surprised at your assertion :
>>all of the memory contents seen by Thread 1, before it wrote to ready,
>> must be visible to Thread 2, after it reads the value true for ready.
I dont' read such info. in JLS.
Please, can you tell us where/how you get your information ?
(This doesn't mean at all, that I don't believe you)
Best regards.
https://google.github.io/guava/releases/snapshot/api/docs/com/google/common/collect/ImmutableMap.html
What if thread 1 executes the method and the method stack is discarded, and then thread2 reads the volatile variable. In this case, what will print(answer) print ?
If thread1 has finished executing the method, all its local stack variables no more exist in main memory. So, what value of "answer" does the Thread2 see ?
I want to know, how exactly are the real live values of local variables communicated to the other threads.
I am little confused, regarding how JVM handles volatile object vs. volatile array?
volatile int arr[] = {1, 2, 3}
arr[0] = 5; // this is not safe as another thread won't see change in this array element
class Flag {
boolean value = true;
}
volatile Flag f = new Flag();
f.value = false; // how is this safe then? Shouldn't this face same issue as array element?
Or have I misunderstood something? Can you help explaining?
The difference with the Flag class is that you can mark the boolean itself volatile.
From my understanding volatile means it reflects the last modified values across the threads.
Please correct me if am wrong.
Please explain in simple words.
you can can also ping me at koti.prasad.1990
Can you please suggest the possible causes with volatile variables in a multi core system?
One thread -Thread1 is doing a write to the volaitle variable, and the other thread Thread2 doing write to a non-volatile variable of the same singleton class. If Thread2 is having old value for volatile variable, will it overwrite the latest value by thread1 for volatile variable . This is for multi core system. I came across this: http://tutorials.jenkov.com/java-concurrency/volatile.html
Can you please clarify
1. I notice that you say that volatile establishes the happen-before relationship between write and read on the SAME object. If a write on volatile is to send the working memory content and a read is to receive memory sent by all other senders before this read point, can we write to volatile variable A and then read from another volatile variable B to achieve the same effect?
2. I really wonder which operations can be reordered? Only w/r to shared variables?
2) You can reorder any operations, as long as the results of the execution are still legal. In practice, it's more common to see elimination of operations that looks like reordering. For example, if you have an array a, and you do
for (int i = 0; < a.size; i++) { ... }
You are very likely to store the value for array.size in a register or on the stack rather than reading it repeatedly from memory on every iteration. From a conceptual point of view, that can be expressed as motion in the sense of "we took all of the reads of array.size and moved them to the beginning of the loop". But really, you are just eliminating the reads. And, it happens that if a is a shared variable, and some other thread writes to it, then weird things can happen, which is why we needed the model to deal with that.
Thanks for the post but I still have question regarding to this question and accepted the answer here: https://stackoverflow.com/questions/32562822/how-does-the-volatile-count-operation-be-made-thread-safe, which claims that "The only time multiple threads are okay to write to a volatile variable without any extra synchronization is if the writes are idempotent (that is, multiple writes have the same effect as a single one)".
But in this accepted answe here: https://stackoverflow.com/questions/3488703/when-exactly-do-you-use-the-volatile-keyword-in-java, it has different conclusion where volatile is NOT enough for compound operation like i++.
Please can you help to take a look? which one is correct?
Thank you!
One of the answers suggests that it's okay to use i++ to indicate progress if you only have a single thread writing to it. That's pretty reasonable. Think of i++ as:
int k = i;
i = k + 1;
If you have an atomic increment - which we don't - both of those operations are done as as single step. When does it matter if those operations aren't done as a single step? If another thread writes to i between them. For example, if i has the initial value 3, and the thread doing the increment reads that value, and then another thread comes around and writes 5 to i, and then the first thread comes back, it will add one to the first value it saw - the 3 - and assign 4 to i. This is called a lost update, because the write of 5 to is lost, and can happen because the increment isn't atomic.
However, if you only have one thread writing to i, that can't happen.
In general, I would discourage use of this pattern unless you are pretty confident you understand the way concurrency works in Java, because it's easy to get it wrong.
Sorry I guess I confuse you. I understand that volatile i++ isn't atomic operation. What I don't undestand is whether volatile i++ is enough with only one single thread writing to it.
Now you confirm it's enough. I guess such pattern is mostly used as a switch variable like below example:
public class Foo implements Runnable {
private volatile boolean stopped = false;
public void stopProcessing() {
stopped = true;
}
public int getItemsProcessed() { return itemsProcessed; }
@Override
public void run() {
while (!stopped) {
processItem(); //process a single item
}
}
}
Again, I recommend that you not use this pattern unless you are pretty confident you understand the way concurrency works in Java, because it's easy to get it wrong.
From a JMM perspective, I can understand that volatile provides visibility and ordering. But I got confused when I saw assembly code about volatile in book. A simple example is as follows:
```java
private static boolean a;
private volatile static boolean b;
public static void foo() {
a = true;
b = true;
}
```
```assembly
0x000002271ed4378c: movabs $0x711dec880,%r10 ; {oop(a 'java/lang/Class'{0x0000000711dec880} = 'Test')}
0x000002271ed43796: movb $0x1,0x70(%r10)
0x000002271ed4379b: movb $0x1,0x71(%r10)
0x000002271ed437a0: lock addl $0x0,-0x40(%rsp) ;*putstatic b {reexecute=0 rethrow=0 return_oop=0}
; - Test::foo@5 (line 8)
```
It is mentioned in the book that 'lock addl' is equivalent to a memory barrier, which can avoid the rearrangement of instructions across the memory barrier, thus providing a volatile order guarantee.
(1) However, is it possible for the cpu to rearrange the two assignment operations before the barrier so that 'b = true' occurs before 'a = true'?
(2) If so, the order provided by volatile from this point of view will not be satisfied. Am I missing something?